
缓存双写不一致
缓存数据库双写不一致
高并发下缓存与数据库双写不一致解决方案
正常的缓存数据库更新的时候应该是先执行线程1,然后执行线程2
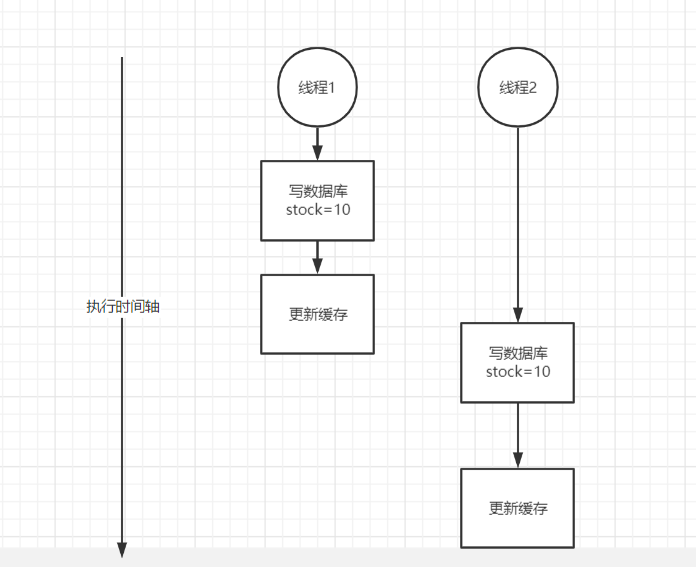
如果线程1卡顿了一下,这时就会造成数据库和缓存不一致的情况线程1把线程2更新的缓存数据给覆盖了
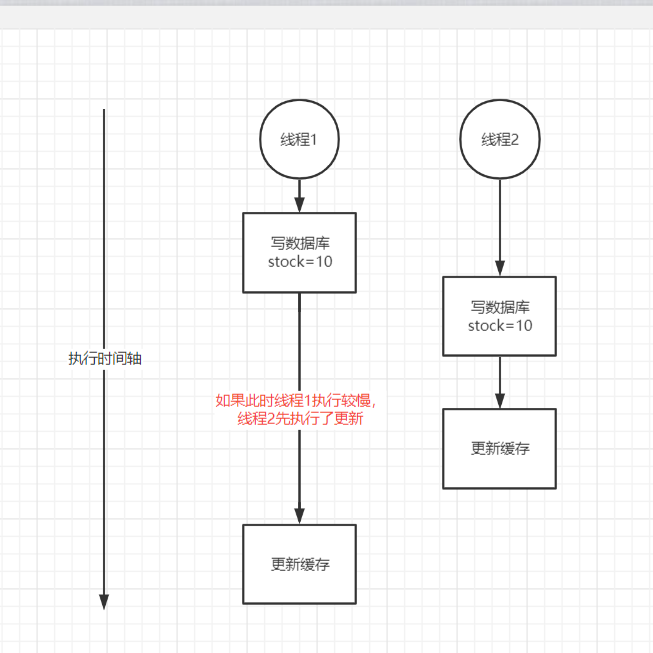
最开始的缓存不一致问题以及解决方案
问题:先修改数据库,再删除缓存,如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据出现不一致。
解决思路:
先删除缓存,再修改数据库,如果删除缓存成功了修改数据库失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致,因为读的时候缓存没有,则读数据库中旧数据,然后更新到缓存中。
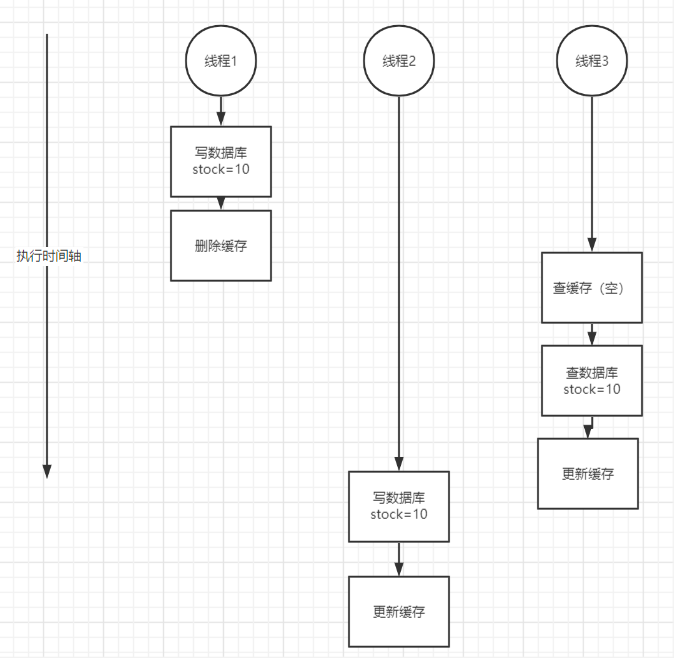
2、并发下数据缓存不一致问题分析
问题:
第一个请求数据发生变更,先删除了缓存,然后要去修改数据库,此时还没来得及去修改;
第二个请求过来去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中;
第三个请求读取缓存中的数据 (此时第一个请求已经完成了数据库修改的操作)。
完了,数据库和缓存中的数据不一样了。。。。
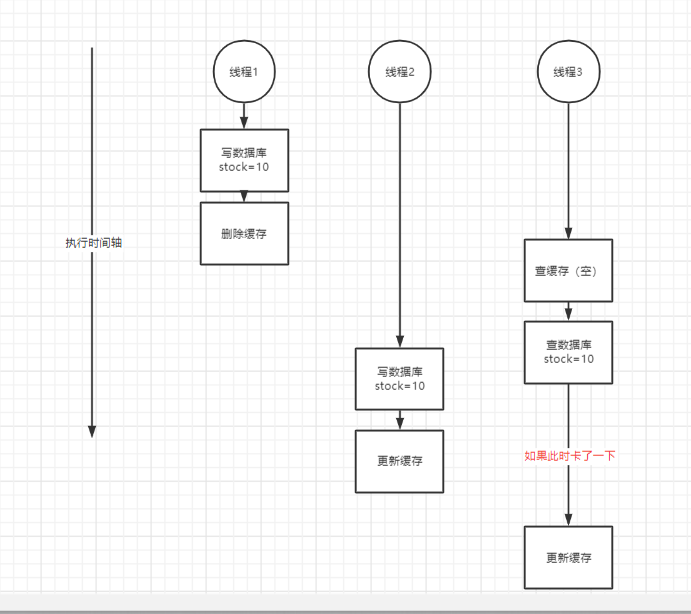
分析原因:
只有在对同一条数据并发读写的时候,才可能会出现这种问题。其实如果说你的并发量很低的话,特别是读并发很低,每天访问量就1万次,那么很少的情况下,会出现刚才描述的那种不一致的场景;但如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的数据库+缓存不一致的情况。
内存队列
数据库的缓存更新与读取操作进行串行化,一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。
1. 首先我们的项目里维护一组线程池和内存队列。
2. 更新数据的时候,根据数据的唯一标识将请求路由到一个jvm队列中,去更新数据库,然后请求结束。
3. 读取数据的时候,先查缓存,如果发现数据不在缓存中,那么将根据唯一标识路由之后,也发送同一个jvm内部的队列中,重新读取数据库后更新缓存,最后请求结束。
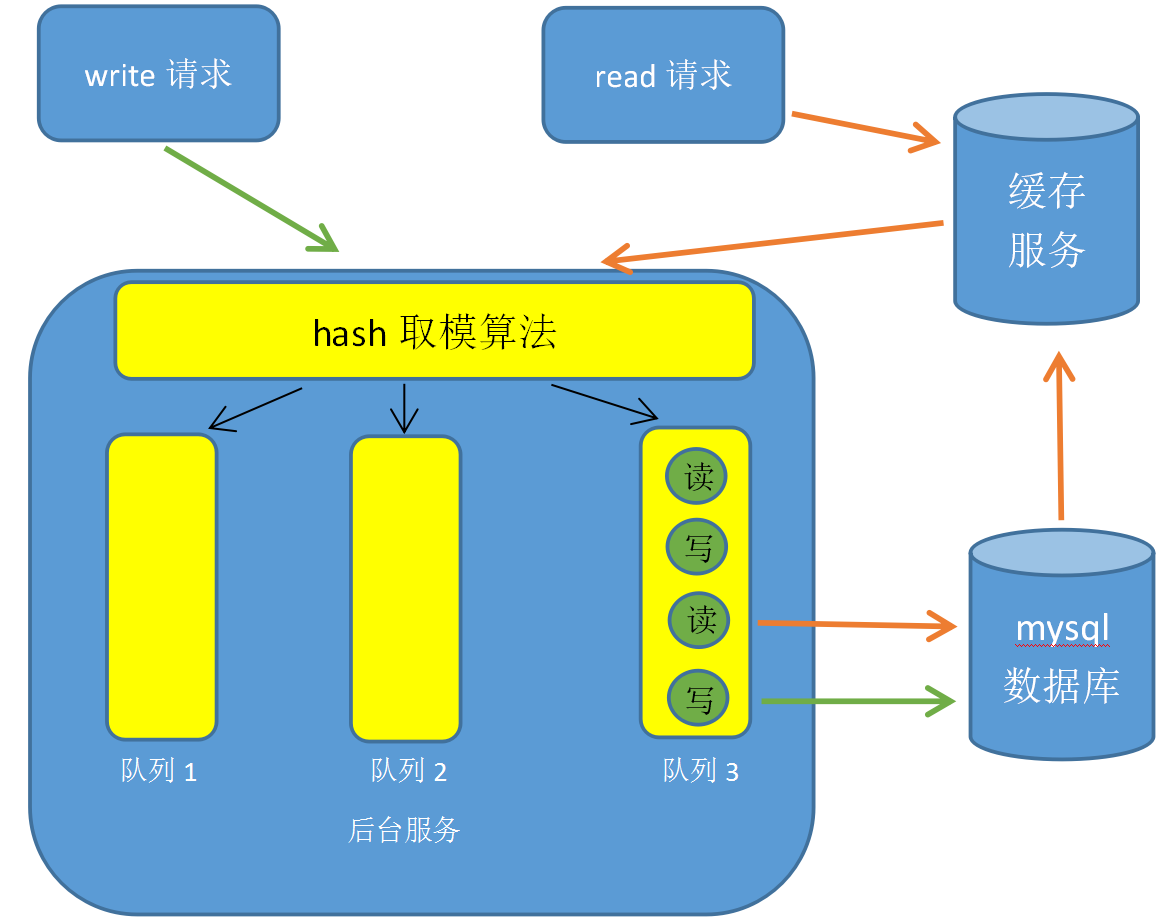
缺点:
1.实现起来麻烦,不同的key可能需要搞不同的队列
2.如果系统挂了,还得还原这些数据,如果出现了异常,还会造成脏数据
延时双删
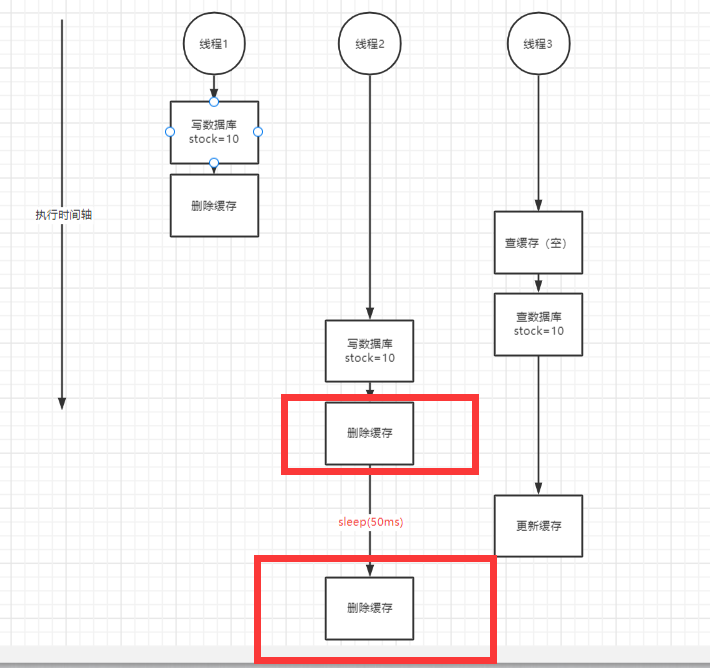
延时双删方案执行步骤
1.删除redis
2.更新数据库
3.延时50毫秒
4.删除redis
- 问题一:为何要延时50毫秒?
这是为了我们在第二次删除redis之前能完成数据库的更新操作。
假象一下,如果没有第三步操作时,有很大概率,在两次删除redis操作执行完毕之后,数据库的数据还没有更新,此时若有请求访问数据,便会出现我们一开始提到的那个问题。 - 问题二: 为何要两次删除redis?
如果我们没有第二次删除操作,此时有请求访问数据,有可能是访问的之前未做修改的redis数据,删除操作执行后,redis为空,有请求进来时,便会去访问数据库,此时数据库中的数据已是更新后的数据,保证了数据的一致性。
缺点:
1.没有从根本上面去解决问题,如果更新缓存时间超过50ms,那么还是失败的,如果要一直保证休眠时间大于更新时间,这样会不会造成阻塞
2.如果一个接口请求有限制时间,这休眠时间会影响用户体验,影响接口的响应速度
分布式锁
如果加分布式锁可以直接保证每个线程的执行顺序,也是一种串行操作
这个还是比较推荐使用的,比内存串行实现简单,而且稳定
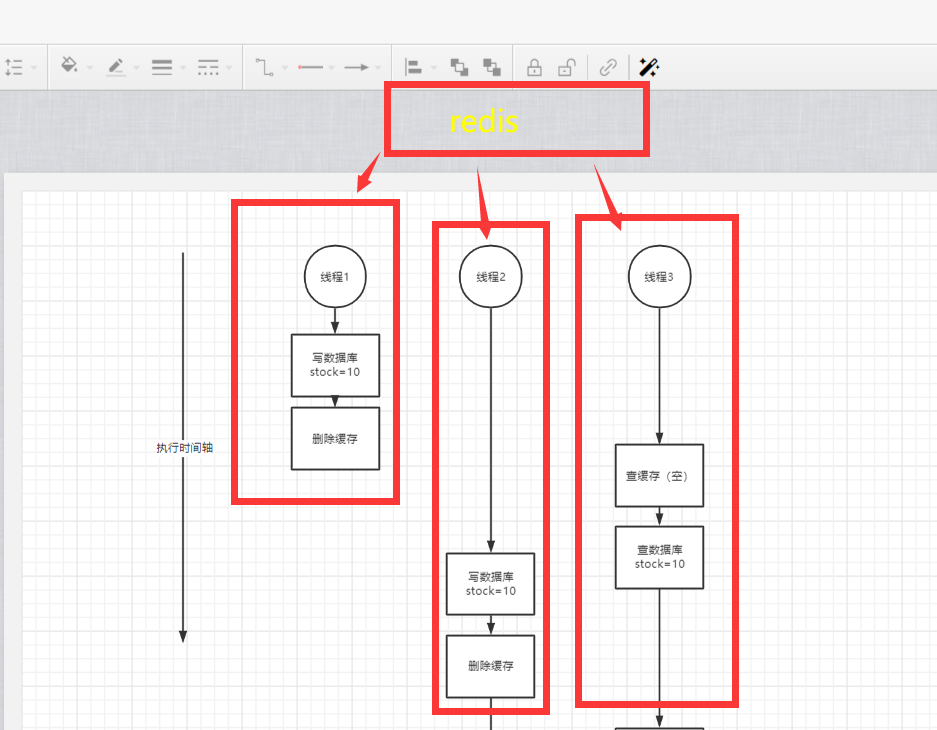
缺点:
1.分布式锁会有性能问题,会导致并发量很低(加锁永远不是最优的方案)
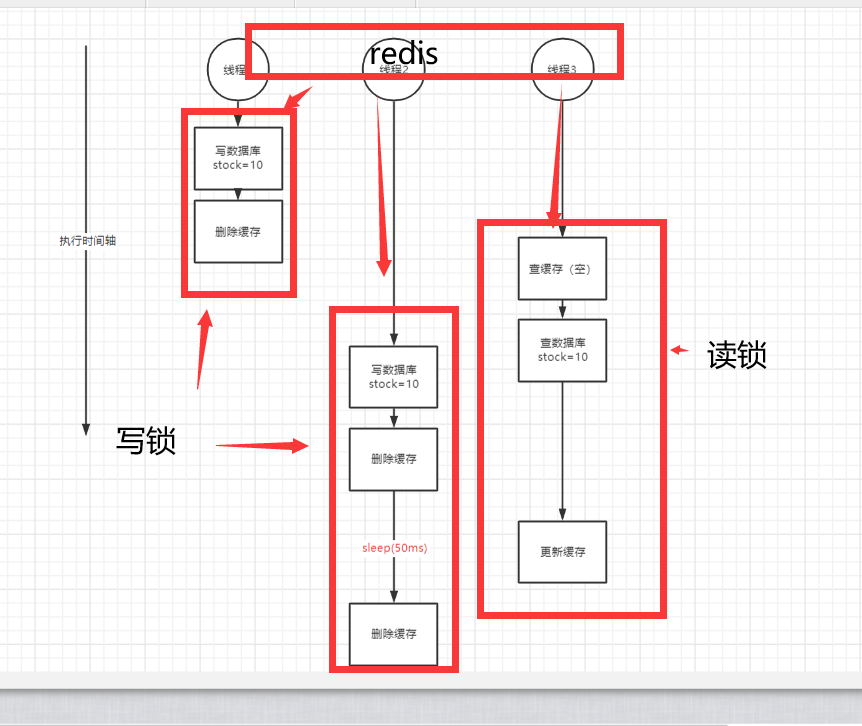
读写锁
redisson中间里面实现了读写锁,读锁与读锁之间是不会互斥的和没加锁一样,写锁与写锁会互斥
一般都是读多写少
总结
一般来说,就是如果你的系统不是严格要求缓存+数据库必须一致性的话,缓存可以稍微的跟数据库偶尔有不一致的情况,那最好不要上述的串行化的这个方案,因为读请求和写请求串行化,串到一个内存队列里去,这样是可以保证一定不会出现不一致的情况。但是,串行化之后,就会导致系统的吞吐量会大幅度的降低,你就需要用比正常情况下多几倍的机器去支撑线上的一个请求。
以上是本人对缓存数据库不一致情况的了解,本人能力有限,如有问题还望包含,也欢迎指正。谢谢!







