
ShardingJDBC简单介绍
ShardingJDBC
介绍
ShardingJDBC是当当网研发的开源分布式数据库中间件,从 3.0 开始Sharding-JDBC被包含在 Sharding-Sphere中,之后该项目进入进入Apache孵化器,4.0版本之后的版本为Apache版本。
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
官方地址:https://shardingsphere.apache.org/document/current/cn/overview/
它定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架
在 maven 的工程里面,我们使用它的方式是引入依赖,然后进行配置就可以了,不用像 Mycat 一样独立运行一个服务,客户端不需要修改任何一行代码,原来是 SSM 连接数据库,还是 SSM,因为它是支持 MyBatis 的
特点
Sharding-JDBC的核心功能为数据分片和读写分离,通过Sharding-JDBC,应用可以透明的使用jdbc访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布。
- 适用于任何基于Java的ORM框架,如:Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL
分库分表的一些核心动作,比如 SQL 解析,路由,执行,结果处理,都是由它来完成的
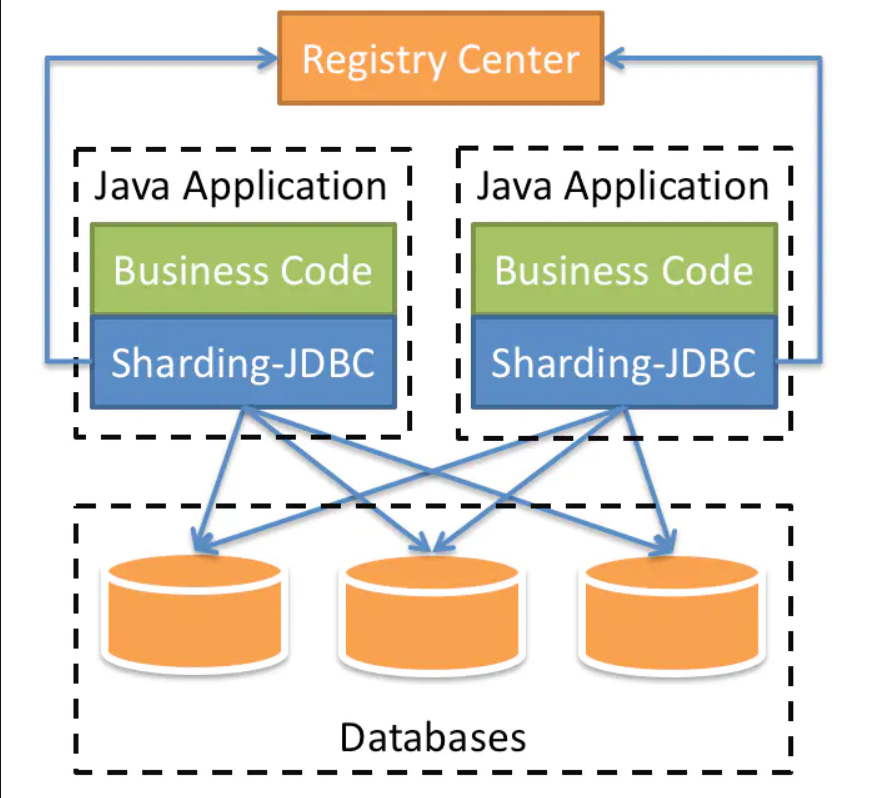
上图展示了Sharding-Jdbc的工作方式,使用Sharding-Jdbc前需要人工对数据库进行分库分表
在应用程序中加入Sharding-Jdbc的Jar包,应用程序通过Sharding-Jdbc操作分库分表后的数据库和数据表,由于Sharding-Jdbc是对Jdbc驱动的增强,使用Sharding-Jdbc就像使用Jdbc驱动一样,在应用程序中是无需指定具体要操作的分库和分表的
主要概念:逻辑表会在 SQL 解析和路由时被替换成真实的表名

性能对比
以下为网上统计数据
1.性能损耗测试:服务器资源充足、并发数相同,比较JDBC和Sharding-JDBC性能损耗,Sharding-JDBC相对JDBC损耗不超过7%
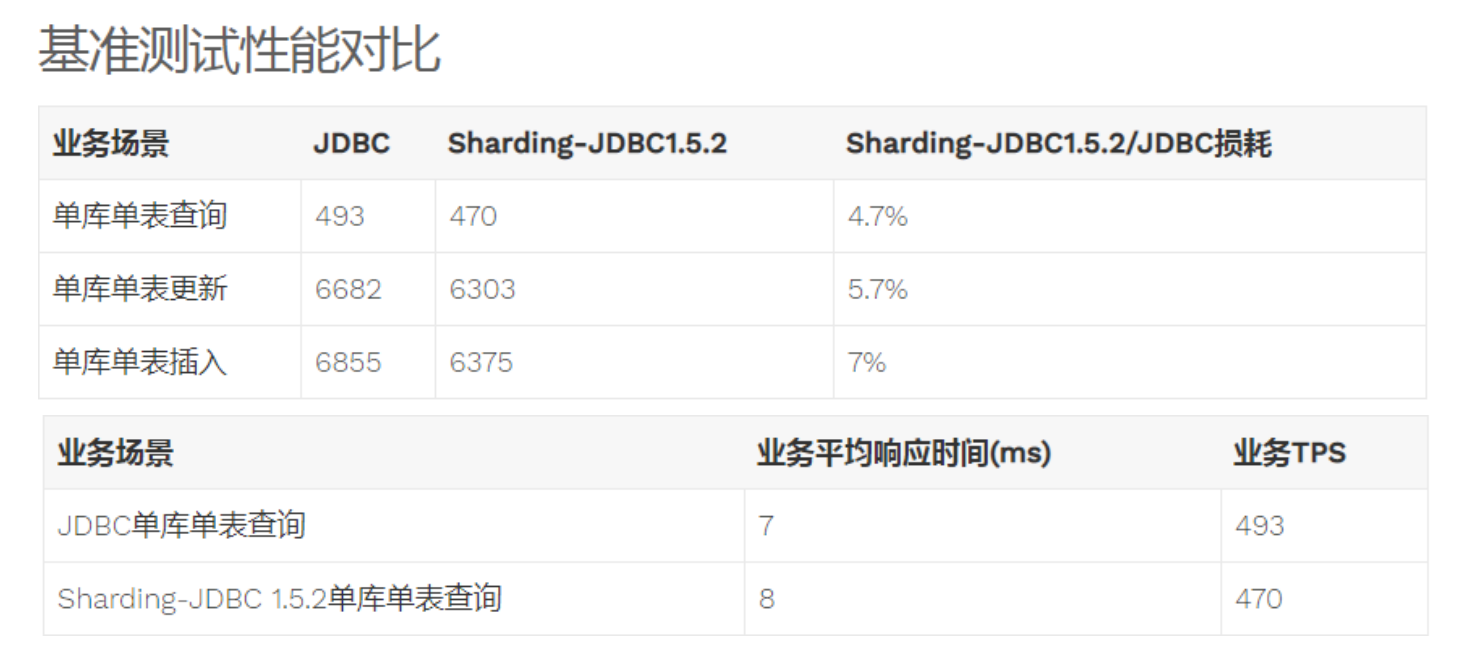
2.性能对比测试:服务器资源使用到极限,相同的场景JDBC与Sharding-JDBC的吞吐量相当
3.性能对比测试:服务器资源使用到极限,Sharding-JDBC采用分库分表后,Sharding-JDBC吞吐量较JDBC不分表有接近2倍的提升。

ShardingJDBC引入
1.引入boot的依赖整合包
1 | <dependency> |
2.创建数据库和表
创建订单库order_db
1
CREATE DATABASE `order_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
在order_db中创建t_order_1、t_order_2表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1`(
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10, 2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
)ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10, 2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
)ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
3.application.properties配置规则
定义数据源
1
2
3
4
5
6
7# 定义数据源m1,并对m1进行实际的参数配置
spring.shardingsphere.datasource.names=m1
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSoure
spring.shardingsphere.datasource.m1.driver‐class‐name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/order_db?useUnicode=true
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root配置数据节点
1
2
3# 指定t_order表的数据分布情况,配置数据节点
# 他分布在m1.t_order_1,m1.t_order_2
spring.shardingsphere.sharding.tables.t_order.actual‐data‐nodes=m1.t_order_$‐>{1..2}配置主键策略
1
2
3# 指定t_order表的主键生成策略为SNOWFLAKE,SNOWFLAKE是一种分布式自增算法,保证id全局唯一
spring.shardingsphere.sharding.tables.t_order.key‐generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key‐generator.type=SNOWFLAKE配置分片算法
1
2
3
4# 指定t_order表的分片策略,分片策略包括分片键和分片算法
# order_id为偶数的数据落在t_order_1,为奇数的落在t_order_2,分表策略的表达式为 t_order_$->{order_id % 2 + 1}
spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.sharding‐column=order_id
spring.shardingsphere.sharding.tables.t_order.table‐strategy.inline.algorithm‐expression=t_order_$‐>{order_id % 2 + 1}日志输出sql
1
spring.shardingsphere.props.sql.show=true
4.数据操作
1 |
|
5.测试
1 |
|
小结
Sharding-JDBC执行流程:SQL解析 => 查询优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并
系统在设计之初就应该对业务数据的耦合松紧进行考量,从而进行垂直分库、垂直分表,使数据层架构清晰明了。
若非必要,无需进行水平切分,应先从缓存技术着手降低对数据库的访问压力。如果缓存使用过后,数据库访问量还是非常大,可以考虑数据库读、写分离原则。若当前数据库压力依然大,且业务数据持续增长无法估量,最后可考虑水平分库、分表,单表拆分数据控制在1000万以内。
注意:并不是所有的sql语句都能支持执行
详细参考:https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/sql/






